Anam Cara-3: Why AI needs a face
Today we're releasing Cara-3, our latest face-generation model. In an independent blind study, participants preferred Anam's interactive avatars over other providers across every metric measured. But why do we care about avatars to begin with?
Why faces and not avatars?
We should really be asking, why faces? And there’s a neurological reason: almost half the human brain is devoted to visual processing, and reading faces is one of the first things we learn to do. Newborns prefer face-like patterns within minutes of birth. There’s emotional signal in faces absent in text or voice. A furrowed brow, a quick glance away, a half-smile mid-sentence. It’s the difference between reading a transcript and watching someone say it. It's why we bother turning our cameras on during video calls.
It doesn’t take much for us to see a face, eg this drunk octopus. A phenomenon called pareidolia.

Faces are also highly accessible. Digital literacy in the US and EU sits at only ~60%, with older adults particularly likely to struggle with text-heavy UIs. This is partly how Anam started: watching my gran struggle to communicate with her iPad and thinking there should be a face she could just talk to.
If faces are such a natural, high-bandwidth interface, the better question might be: why not avatars? Why don't more products have a digital face you can talk to?
Talking faces are hard
Our view is simple: if people could speak to high-quality avatars instead of using traditional UIs, they would. The only blocker has been the tech itself. Recent progress in conversational AI has only just made this possible, but we’re a long way off a single multi-modal model which handles everything. Today it requires orchestrating a complex stack.
The conversational layer. Before you even get to the face, you need accurate transcription, emotion recognition, turn-taking prediction, a whole agentic layer (text generation, tool calling, RAG etc.), backchannel handling (the "yeah"s and "mm-hmm"s to signal agreement without yielding the turn), and voice generation with natural prosody and emotional range.
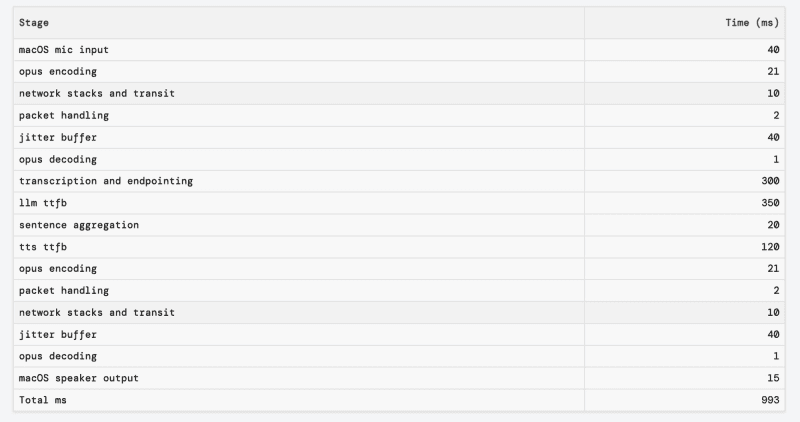
Latency. Results show responsiveness as the strongest predictor of overall experience. Humans typically respond in under 500 milliseconds, which is faster even than it takes to form a conscious thought (we preload our responses before the other person has finished). This is a high bar, when you consider the amount of processing steps required.
What a sub-second response typically looks like for “just” a voice-agent. The numbers our engineers obsess over. Source: https://voiceaiandvoiceagents.com/.
Visual layer. Pixel-perfect lip sync, natural head motion and eye gaze, emotionally congruent expressions, active listening, identity consistency across an entire conversation, and non-repetitive motion. This is before you get to more subtle aspects eg tongue movement, hair physics, or clothing deformation. The margin of error can be small, a few pixels of drift in eye gaze is enough to notice.
Systems engineering. Real-time avatar streaming isn't only a research problem. You need constant, smooth video playback under variable internet connections, unpredictable upstream throughput, and graceful transitions in and out of idle states. What happens when a customer's LLM slows down mid-sentence? What about a network latency spike?
Getting all this right in unison often feels like an elaborate magic trick, and it just takes one of these layers to fail for the house of cards to cascade down and suddenly the whole thing feels uncanny.
How we built Cara-3
Cara-3 advances the visual layer. It uses a two-stage pipeline: the first stage is audio-to-motion. A diffusion transformer takes audio input and produces motion embeddings: head position, eye gaze, lip shape, facial expression, all derived from the audio signal. This is where the expressivity of the avatar comes from. You can think of these embeddings as the mask in the mirror in Shrek. All expression, without colour or texture.
Claude warned not to use this reference else I risk losing gen-z readers.

The second stage is motion-to-face. A separate rendering model takes these motion embeddings and applies them to a reference image, producing video frames. Separating motion from rendering like this means we can animate any face without retraining, allowing us to create custom avatars from an image almost instantly.
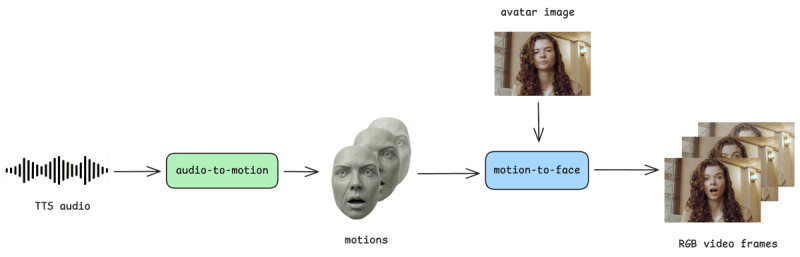
The two models are parameter efficient, and can run in sequence within ~70ms TTFF (time-to-first-frame) on an H200. This lets us run many avatar sessions on a single GPU, enabling a highly scalable, cost-efficient service. Finding this quality-latency-efficiency point took many thousands of research experiments. The core algorithm behind audio-to-motion is flow matching, and off-the-shelf formulations weren’t stable enough for this task. We had to develop a novel variant that worked specifically for efficient, real-time face generation. If you want to understand the fundamentals of this, one of our researchers wrote a good primer on flow matching.
As important as the architecture, Cara-3 depends on training data. We’ve found for this problem quality > quantity, and rely heavily on data cleaning / filtering. Existing pipelines made it hard to iterate quickly (eg rerunning expensive steps for partial updates), so we built our own, and recently open-sourced the backbone: Metaxy.
Independent evaluation
Mabyduck ran two blind evaluations comparing interactive avatars from Anam, HeyGen, Tavus, and D-ID. Hundreds of participants played 20 Questions with avatars from each provider. The game is easy to explain, low cognitive load, and the avatar speaks for most of the interaction, giving participants time to properly assess what they're looking at. More on their methodology.
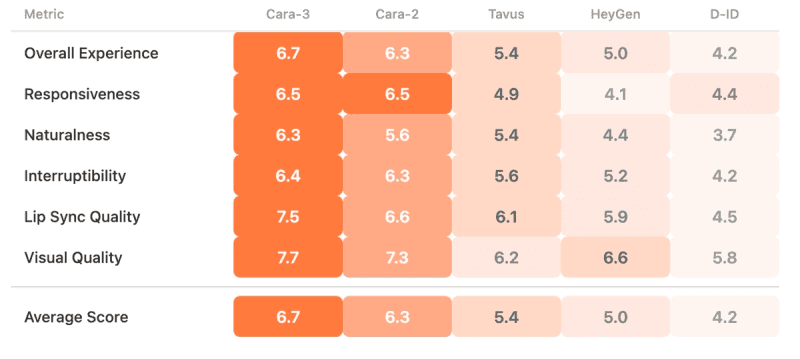
For reference, we'd expect a real human to score close to 10.
Participants preferred Anam's avatars overall (p < 0.001), with Cara-3 scoring 24% higher than the closest competitor on average. Compared to Cara-2, the biggest gains were in lip sync (6.6 → 7.5) and naturalness (5.6 → 6.3). But perhaps the most interesting finding was what drives that preference. Responsiveness had the highest correlation with overall experience (Spearman 0.697), well above visual quality (0.473). Microsoft published a study showing realism strongly predicts trust and affinity for non-interactive avatar videos [1]. But in an interactive setting, how quickly the avatar responds seems to matter more than how good it looks.
The road ahead
We might have scored highest in the study, but measured against actual humans, the gap is still large. Better active listening, more varied gestures, finer emotional control, more natural eye movement, less repetitive motion over long conversations. Each its own research problem, and we have a long list beyond these.
While we have a lot of work still to do, we’re bolstered by the number of applications we’re seeing with Anam today. From solo devs to enterprise, across language learning, sales coaching, med tech, virtual training, and more. One customer reported 70% of users preferred avatars over voice when given the choice. Others have seen up to 24% higher conversion and 44% higher retention when using Anam as the face of their agents.
Voice AI crossed a threshold recently. It works well enough that millions of people use it every day without thinking about it. We think face AI is approaching a similar point. The technology is getting good enough, fast enough, and cheap enough that talking to a face on screen will feel unremarkable. We're not there yet, but Cara-3 brings us closer.
Try it
Talk to Cara-3 at anam.ai, no sign-up required.
To build with it: create an avatar at lab.anam.ai, or jump into code examples using one of our SDKs at anam.ai/cookbook. We also support several integrations, eg livekit, pipecat or elevenlabs agents.
Explore more articles






© 2026 Anam Labs
HIPAA & SOC 2 Certified