Metaxy: Metadata Management for Incremental Multimodal Data Pipelines
At Anam, we are making a platform for building real-time interactive avatars. One of the key components powering our product is our own video generation model.
We train it on custom training datasets that require all sorts of pre-processing of video and audio data: extract embeddings with ML models, use external APIs for annotation and data synthesis, and so on. We've encountered significant challenges with implementing efficient and versatile sample-level versioning (or caching) for these pipelines, which led us to develop and open-source Metaxy: the framework which solves metadata management and sample-level versioning for multimodal data pipelines.
Metaxy connects orchestrators such as Dagster that usually operate at table (or asset) level with low-level processing engines (such as Ray), allowing us to process exactly the samples that have to be processed at each step and not a sample more.
We have been dogfooding Metaxy at Anam since December 2025. We are running millions of samples through Metaxy. All the current Metaxy functionality has been built for our data pipeline and was used to prepare training data for our new model: Cara 3.
The Little Change
A few months ago we decided to introduce a little change into the data preparation pipeline. At that time, we were using a custom data versioning system which tracked a version for each sample. The system could compute a fingerprint for each step based on a manually specified code_version on the step and the upstream steps. We computed it for each row in the dataset.
The change we wanted to introduce was very simple: we wanted to crop our videos at a new resolution. This implied changing the code_version of the cropping stage, and the downstream steps would be re-computed automatically. However, we also noticed an unpleasant outcome. Right after the cropping step, our pipeline branched into two regions:

Half of the downstream steps were not even using the cropped video frames. They only operated on the audio part. But our data versioning system was unaware of this detail and would re-compute them anyway. This means running our custom audio ML models on the entire training dataset: very expensive and absolutely unnecessary.
This was the moment I realized there was something wrong with our naive approach to data versioning. The idea of Metaxy - the project we are going to discuss in this blog post - was born.
A Glimpse Into Multimodal Data
As the software world is being eaten by AI, more teams and organizations are starting to interact with multimodal data pipelines. Unlike traditional data engineering workflows, these pipelines are not dealing just with tables, but also with texts, images, audio, videos, vector embeddings, medical data, and so on.
Multimodal data pipelines can be very unique, with requirements and complexity varying from use case to use case. Whether calling AI APIs over HTTP, running local ML inference, or simply invoking ffmpeg, there is something in common: compute and I/O gets expensive very quickly.
When traditional (tabular) data pipelines are re-executed, it typically doesn't cost much. Sure, Big Data exists, and Spark jobs can query petabytes of tabular data, but in reality very few teams actually run into these issues. That's the reason behind the Small Data movement success: the median Snowflake scan reads less than 100MB of data, and 80% of organizations have less than 10TB of data! Therefore, re-running a tabular pipeline is usually fine. It's also much easier to do than to implement incremental processing.
Multimodal pipelines are a whole different beast. They require a few orders of magnitude more compute, data movement and AI tokens spent. Accidentally re-executed your Whisper voice transcription step on the whole dataset? Congratulations: $10k just wasted!
That's why with multimodal pipelines, implementing incremental approaches is a requirement rather than an option. And it turns out, it's damn complicated.
Introducing Metaxy
Metaxy is the missing piece connecting traditional orchestrators (such as Dagster or Airflow) which usually operate at a high level (e.g. update tables) with the sample-level world of multimodal pipelines.
Metaxy has two features that make it unique:
It is able to track partial data updates.
It is agnostic to infrastructure and can be plugged into any data pipeline written in Python.
Metaxy's versioning engine:
operates in batches, easily scaling to millions of rows at a time.
runs in a powerful remote database or locally with Polars or DuckDB.
is agnostic to dataframe engines or DBs.
is aware of data fields: Metaxy tracks a dictionary of versions for each sample.
Data Fields
One of the main goals of Metaxy is to enable granular partial data versioning, so that partial updates are recognized correctly. In Metaxy, alongside the normal metadata columns, users can also define and version data fields:

Data fields can be arbitrary and designed as users see fit. The key takeaway is that data fields describe data (e.g. mp4 files) and not tabular metadata. Then, you can run a few lines of Python code:
which does a lot of work behind the scenes:
joining state tables for upstream steps
computing expected data versions for each row - this is the most complicated step. It is complicated because each version is a dictionary, and each field in the dictionary may depend on its own subset of upstream fields
loading the state table for the step being resolved and comparing versions with the expected ones
returning new, stale and orphaned samples to the user
Once the user gets the increment object (by the way - it can be lazy!), they can decide what to do with each category of samples: typically new and stale are processed again, while orphaned may be deleted.
Partial Data Dependencies
Metaxy solves the "little change" problem by being aware of partial data dependencies.
Consider 3 Metaxy features (that's how Metaxy calls the data produced at each step): video files (video/full), Whisper transcripts (transcript/whisper), and video files cropped around the face (video/face_crop):

Separate information paths for audio and frames are color-coded. Notice how there are clear field-level, or partial data dependencies between features. Each field version is computed from the versions of the fields it depends on. Field versions from the same feature are then combined together to produce a feature version.
It is obvious that the text field of the transcript/whisper feature only depends on the audio field of the video/full feature. If we decided to resize video/full, then transcript/whisper doesn't have to be recomputed.
Metaxy detects this kind of "irrelevant" updates and skips recomputation for downstream features that do not have fields affected by upstream changes. This is achieved by recording a separate data version for each field of every sample of every feature:
id | metaxy_provenance_by_field |
|---|---|
video_001 |
|
video_002 |
|
video_003 |
|
video_004 |
|
Example: Partial Data Updates
Here is what Metaxy code actually looks like. Consider a video processing pipeline with these features:
Running metaxy graph render --format mermaid produces this graph:
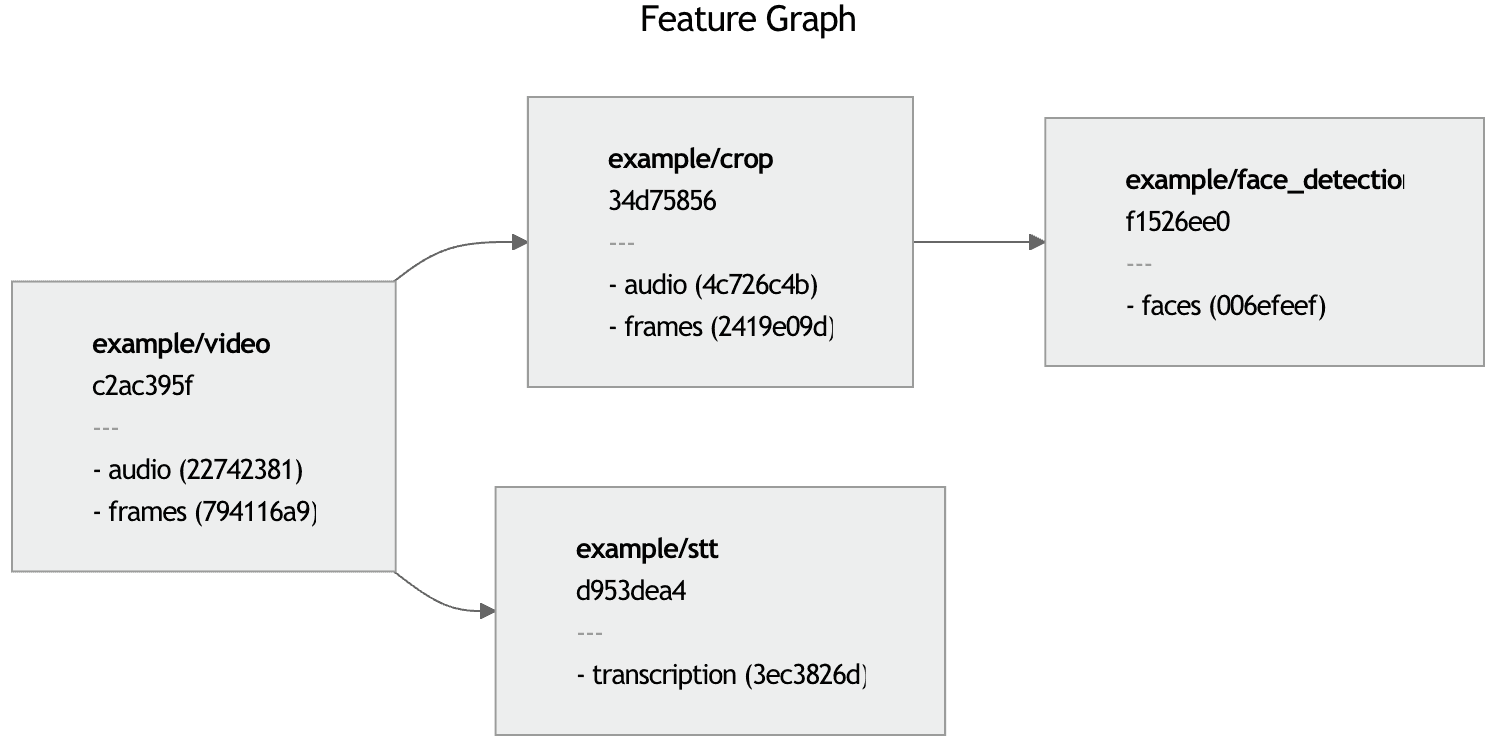
Tracking Definition Changes
Imagine the audio field of the Video feature changes (perhaps something like denoising has been applied):
Here is how the change affects feature and field versions through the feature graph:
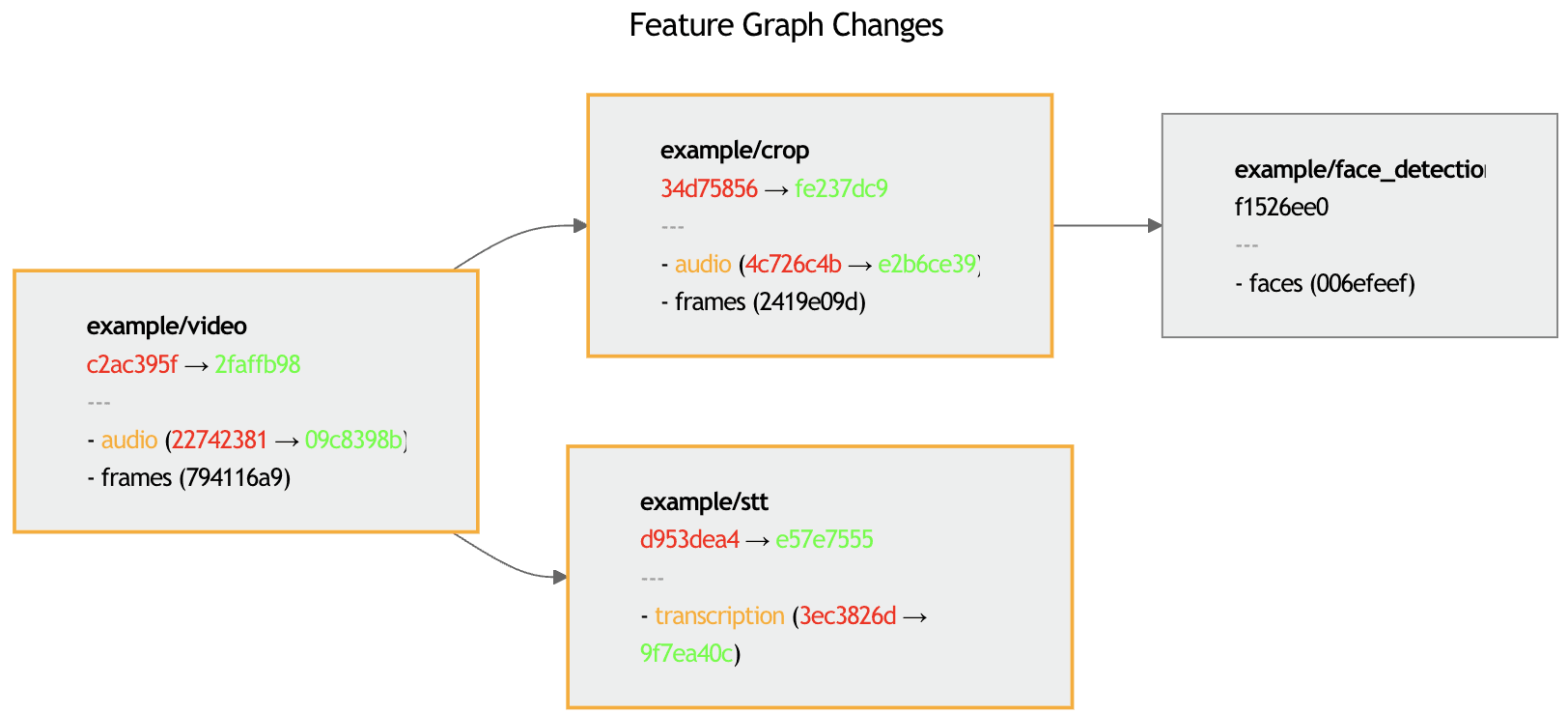
Note:
Video,Crop, andSpeechToTexthave changedFaceDetectionremained unchanged (depends only onframesand not onaudio)Audio field versions have changed throughout the graph
Frame field versions have stayed the same
Incremental Computations
The single most important piece of code in Metaxy is the resolve_update method. For a given feature, it takes the inputs (metadata from the upstream features), computes the expected provenances for the given feature, and compares it with the current state in the metadata store.
The Python pipeline needs to handle the result of the resolve_update call:
The increment object has attributes for new upstream samples, samples identified as stale, and samples that have been removed from the upstream metadata.
The Challenge of Composability
As mentioned earlier, incremental pipelines are diverse: they often run in unique environments, require specific infrastructure, different cloud providers (including Neoclouds), or scaling engines such as Ray or Modal.
One of the goals of Metaxy was to be as versatile and agnostic as possible and support this variety of use cases. Metaxy had to be pluggable in order to be usable by different users and organizations.
And it turns out, this is possible! 95% of metadata management work done by Metaxy is implemented in a way that's agnostic to databases, and can even run locally with Polars or DuckDB!
This is only possible due to the incredible amount of work that has been put into the Ibis and Narwhals projects. Ibis implements the same Python interface (not a typical DataFrame API) for 20+ databases, while Narwhals does the same for different DataFrame engines (Pandas, Polars, DuckDB, Ibis, and more), converging everything to a subset of the Polars API.
Narwhals (or Polars) expressions are the GOAT for programmatic query building. Most of Metaxy's versioning engine is implemented in Narwhals expressions, while a few narrow parts had to be pushed back to specific backends.
The importance of this cannot be stressed enough. Entire new generations of composable data tooling can be built on top of Narwhals - and of course, none of this would be possible without Apache Arrow.
Metaxy at Anam
At Anam, we use Metaxy to orchestrate our video generation training data pipeline. The pipeline processes raw video and audio files through multiple stages: face detection, cropping, audio extraction, transcription, embedding generation, and more.
Before Metaxy, change tracking was complex and produced a lot of false positives. Now, Metaxy ensures we only reprocess exactly the samples affected by each change, saving us significant compute costs and time.
We are thrilled to help more users solve their metadata management problems with Metaxy. Please do not hesitate to reach out on GitHub, read our docs here, and uv pip install metaxy!
Frequently Asked Questions
What is Metaxy?
Metaxy is an open-source framework for sample-level versioning in multimodal data pipelines. It connects orchestrators like Dagster or Airflow with low-level engines like Ray, ensuring only affected samples are reprocessed. Anam built it to power the training pipeline for Cara 3.
Why does sample-level versioning matter for multimodal pipelines?
Rerunning tabular pipelines is cheap. Rerunning video, audio, and embedding pipelines is not. A single accidental re-execution of a transcription step on a full dataset can cost $10k. Metaxy tracks changes at the field level so only what changed gets reprocessed.
How does Metaxy handle partial data dependencies?
Each data field tracks its own version hash independently. If only audio changes, downstream steps that depend on video frames are skipped automatically. Metaxy computes this per field, per sample, not per row.
What infrastructure does Metaxy support?
Metaxy is infrastructure-agnostic. It runs against any database or locally with Polars or DuckDB, and scales to millions of rows. It is built on Narwhals and Ibis, giving it a unified interface across 20+ databases and DataFrame engines.
Acknowledgments
Thanks to Georg Heiler for contributing to the project with discussions and code, and thanks to the open source projects Metaxy has been built with: Narwhals, Ibis, and others.
Explore more articles






© 2026 Anam Labs
HIPAA & SOC 2 Certified