Beta Feature: Audio passthrough mode is currently in beta. APIs may change as we continue to improve the integration.
Want to use ElevenLabs Agents with Anam? We recommend the server-side ElevenLabs integration instead—it’s simpler and has lower latency. This page covers the client-side approach for when you need direct control over the audio pipeline.
View Example
Full source code for the ElevenLabs conversational agent with Anam avatar (client-side).
How It Works
The integration uses Anam’s audio passthrough mode, where Anam renders an avatar that lip-syncs to audio you provide—without using Anam’s own AI or microphone input.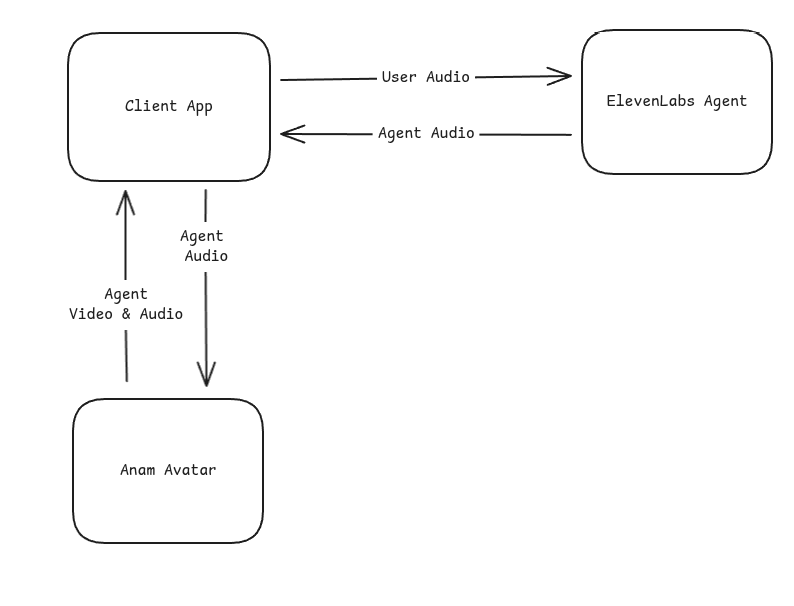
Quick Start
Prerequisites
- An account with your TTS provider (ElevenLabs used in this example)
- Anam account with API access
- Node.js or Bun runtime
- Modern browser with WebRTC support (Chrome, Firefox, Safari, Edge)
Installation
chatdio provides microphone capture utilities used to send user audio to ElevenLabs.
Basic Integration
Here’s the core pattern for connecting an external TTS source to Anam:Full Example
Project Structure
Server: Create Anam Session
Your server creates an Anam session token withenableAudioPassthrough: true:
config.ts
Client: ElevenLabs Module
Handle the WebSocket connection and microphone capture:elevenlabs.ts
Client: Main Integration
Wire everything together:client.ts
Cleanup
Stop the conversation and release resources:Configuration
Environment Variables
Get your API credentials
You’ll need credentials from both services:
| Service | Where to get it |
|---|---|
| Anam | lab.anam.ai → Settings → API Keys |
| ElevenLabs | elevenlabs.io → Agents |
ElevenLabs Agent Setup
When configuring your ElevenLabs agent, set the output audio format to match Anam’s expectations:| Setting | Value |
|---|---|
| Format | PCM 16-bit |
| Sample Rate | 16000 Hz |
| Channels | Mono |
Choosing an Avatar
Stock Avatars
Browse ready-to-use avatars in our gallery. Copy the avatar ID directly into your config.
Custom Avatars
Create your own personalized avatar in Anam Lab with custom appearance and style.
Audio Passthrough API
To guide avatar expression in audio passthrough sessions, send Director Notes cues over the data channel. See Director Notes.
createAgentAudioInputStream()
Creates a stream for sending audio chunks to the avatar for lip-sync. Must be called afterstreamToVideoElement() resolves (the session must be started first).
Audio encoding format. Only
pcm_s16le (16-bit signed little-endian PCM) is supported.Sample rate in Hz. Should match your TTS provider output (typically 16000).
Number of audio channels. Use
1 for mono.sendAudioChunk()
Send a base64-encoded audio chunk for lip-sync rendering.endSequence()
Signal that the current audio sequence has ended. This helps Anam optimize lip-sync timing and handle transitions.- Your TTS provider signals the agent has finished speaking
- The user interrupts (barge-in)
Handling Interruptions
When a user speaks while the agent is talking (barge-in), your TTS provider sends an interruption event. Handle it by interrupting the avatar and ending the audio sequence:interruptPersona() stops the avatar’s current lip-sync animation immediately. endSequence() tells the audio stream that the current sequence is done. Both are needed—without interruptPersona(), the avatar may continue playing buffered audio.
Performance Considerations
Latency
This integration combines two real-time services, which adds latency compared to using Anam’s turnkey solution:| Path | Typical Latency |
|---|---|
| User speech → ElevenLabs STT | 200-400ms |
| ElevenLabs LLM processing | 300-800ms |
| ElevenLabs TTS → Anam avatar | 100-200ms |
| Total end-to-end | 600-1400ms |
Browser Compatibility
The integration requires WebRTC support. Tested browsers:| Browser | Support |
|---|---|
| Chrome 80+ | Full support |
| Firefox 75+ | Full support |
| Safari 14+ | Full support |
| Edge 80+ | Full support |
Mobile browsers are supported but may have higher latency on cellular networks.
Billing
When using audio passthrough mode:- Anam: Billed for avatar streaming time (session duration)
- TTS Provider: Billed separately for STT, LLM, and TTS usage
When to Use This Approach
This client-side approach is a good fit when you:- Need direct control over the audio pipeline in the browser
- Want to use client-side tools with your TTS provider’s agent
- Have an existing client-side integration you want to add avatars to
Troubleshooting
Avatar lips not moving
Avatar lips not moving
- Verify audio format matches (PCM16, 16kHz, mono)
- Check that
sendAudioChunk()is receiving data - Ensure the audio input stream was created successfully
- Look for errors in browser console
Audio/lip-sync out of sync
Audio/lip-sync out of sync
- Call
endSequence()when agent responses complete - Ensure you’re handling interruptions correctly
- Check network latency to both services
No audio from agent
No audio from agent
- Verify your TTS provider agent is configured correctly
- Check the WebSocket connection is established
- Look for audio events in the message handler
- Confirm your agent ID is correct
Microphone not working
Microphone not working
- Check browser permissions for microphone access
- Ensure
echoCancellationis enabled to prevent feedback - Verify the microphone is sending data at 16kHz
Session token errors
Session token errors
- Verify your
ANAM_API_KEYis valid - Check that
enableAudioPassthrough: trueis set in the session request - Ensure the avatar ID exists in your account
Resources
Server-Side Integration
Recommended: simpler setup with lower latency
Client-Side Source Code
Full source code for the client-side integration
Cookbook: Expressive Voice Agents
Guide to using ElevenLabs V3 expressive voices with Anam
Avatar Gallery
Browse available stock avatars